SchemaEditor
The major task of the schema-editor is to create a XML-Repository and to manage it. A user of the schema-editor is assumed as a databases-administrator. The user has knowledge about the structure of the data and its representation in the relational model. The SchemaEditor possesses the following functional characters:
To convert Data Dictionary of a relational databases to a XML-Repository.
Add semantic information to the Repository. By using the reverse engineering colleges, which can run either completely automatically or by questioning the user. The user can also add the semantic information separately.
Add and editing the Meta-information of the attributes.
Create and drop of tables
Create and drop of table rows
Create database from XML-schema
Create XML and SQL database dumps
Import and export schema between all supported databases
Migrate data and schema between all supported databases
 | In the opposite to other DB-manager SchemaEditor does not work directly on data base schema. The data base schema is picked out and converted into own data structure (Repository), which can be stored also as XML file (xmlschema) and loaded again. This structure is not data base system specific. In this way the editing of DB-repository without db-connection is possible. SchemaEditor can produce Data Definition SQL for each data base system supported by Xdobry Also the changes of the db-schema can be generated as DDL-Sql statement. |
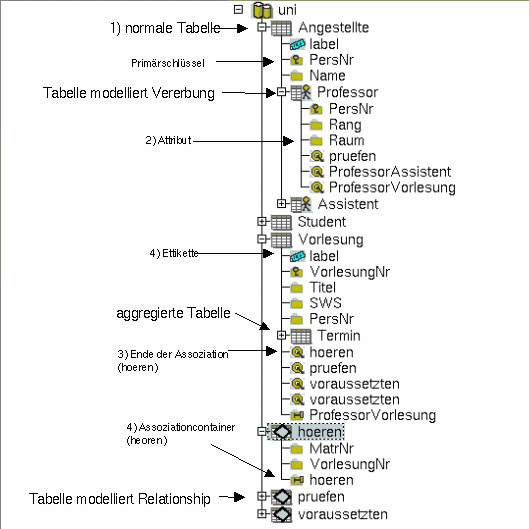
Table
Attribute
Associationcontainer
Assoziationtarget
Tables-Label
Attribute-groups (structured attributes)
Reverse engineering
The relational model is strong value oriented. It knows no association (relationship) types. The association are represented as a foreign key. The tables can represent an Entities (Objects), relations-ship, partial objects (by subtypes modeling) or properties (e.g. , lists of the attributes). With reverse engineering the semantic meaning, also the information how the relational model is to be interpreted, are achieved. This information is coded only as the names of the attributes. Neither MySql nor Postgresql support the definition of foreign-keys. This is big disadvantage by the production of the forms. The reverse-engineering algorithms are based only on the relational schema, the data content is not evaluated. It were implemented three reverse-engineerings algorithms. The foreign-key-search is a basis for other algorithms (out of the subtype-search).
- Foreign key-search
Find all attributes with the same name as the primary keys of the other tables, however, the Prim-attributes are not Prim-attribute or are not a single Prim-attribute. Limitation: object tables consist only single prim-attribute. No Recursive relations! Action: a simple reference is constructed. Association-container gets the foreign key. Association-Target gets the primary key. It is a basis for the other algorithms.
- Subtype-search
Search for the subtype. Find all tables having one primary keys of the same name. They(you) must determine the father's table themselves. With Multi-level inheritance (grandson's objects' the action must be executed repeatedly. Limitation: object tables consist only single prim-attribute.
- Find association-tables
These reverse engineering technology is based on the step "foreign-key-search". The tables should be determined which model Relationship (e.g., n:m Relationship). Algorithm: Find all tables whose primary key exists(consists) of several foreign keys or several foreign keys and no unambiguous primary key have. Action: the Relationship-tables are particularly drawn. N:m or n:m:z. Relations are recognized. Relations may have own Attributes.
- Suggest Aggregation
These reverse engineering technology is based on the step "foreign-key-search". Suggest the Aggregation (composition) of the tables (Embedded tables). The algorithm shows only the suggestions, the Aggregation-semantics can be determined only by used. Suggestions: 1. All tables only a foreign key have. It can exist still farther Aggregation. If they check 1:n associations
Define abstractions
Three sorts can be defined by abstractions of the conceptual databases modeling: association, Aggregation (composition) specialization (subtypes). The definition takes place gradually with the help of assistants.
- Association
Is the most difficult to define. It corresponds to the Relationship of the ER-model. It are placed the following questions.
Is the association recursive? There are relations (Relationship) between the objects of the same type.
Is there a table with references? If the association with help had to be illustrated by additional tables what is relations always the case with the N:M, or how with 1:N relations there is only a reference in one of the table
Degree of the Relationship: with the N:M it is 2 with the N:M:O it is 3
Rolle-names: (not obligatorily)
Existence dependence: Do not become till present farther supported, however, can be defined here
An association is understood as container (collection) with references to objects. The collection can be modeled either as a separated table with references or as a reference in an object (1:n). Around an association become to model two new edeg-types added:Assozitaioncontainer With references and Assoziationtarget With objects. An association container and at least two Assoziatontargets belongs to every association (relationship). The associations (association container) possesses an unambiguous name. In this way can also be modeled complex association such as recursive 1:n and n:m relations and relations the higher Granularity n:m:s:r. Correspondence in ER-modelFigure 8 in the Section called Association (form-link)
- Aggregation
Here it is about the possibly modeling of nested tables. They are shown as embedded (nested) forms from FormServer. One must specify: the container-table, which element-table and reference, foreign key in the element table which points at primary key in container-table. Correspondence in ER-modelFigure 10 in the Section called Aggregation
- Subtypes (inclusion dependency)
Also known as inheritance or generalization. There is always a father object and a child object which are modeled in two tables (primary key heritage). One must also give the inherited primary key. Correspondence in ER-model Figure 9 in the Section called Specialization (inheritance).
DB-Schema create and modify
Xdobry can be used for modellung data base schema. Tables and columns can be created, modified and deleted. Xdobry does not work directly Dictionary (schema) but has own data base system independent representation of the schema, which can be put down as XML file. It is possible to develop schema without connection data base and install many databases from one XML-repository. The Xdobry schema is based on ER-diagram and contains more semantic information than the Data-dictionary of data base.
Creating new schema
For that data base connection is not necessary. By the menu Schema->New new data base schema is created. Use context sensitive menus (select a leaf and right mouse button click) can be used to creat tables and columns.
Xdobry own has data types system, in addition, which is set on Mysql data base system but supports other types (like Money or Boolean).
Table 1. supported DB-Types and type conversion
| Xdobry | Mysql | MS Access | MS SQL | Postgres | Oracle |
|---|---|---|---|---|---|
| decimal | Decimal, numeric | Currency, money | monay | money | number |
| double | double | float | float | double | double |
| float | float | real | real | real | float |
| int | int | Integer, int | int | Integer, int | int |
| smallint | Smallint, tinyint | smallint | smallint | smallint | smallint |
| Boolean | smallint | boolean | boolean | Boolean, bool | Number(1) |
| text | Text, mediumtext, tinytext | Memo, LONGTEXT, LONGCHAR, MEMO, NOTE, NTEXT | image | text | clob |
| datetime | Datetime, date, time | datetime | timestamp | timestamp | timestamp |
| timestamp | timestamp | datetime | datetime | timestamp | timestamp |
| enum | enum | Varchar(50) | Varchar(50) | Varchar(50) | Varchar(50) |
| set | set | Varchar(50) | Varchar(50) | Varchar(50) | Varchar(50) |
| varchar | varchar | TEXT(n), ALPHANUMERIC, CHARACTER, STRING, VARCHAR, CHARACTER VARYING, NCHAR, NATIONAL CHARACTER, NATIONAL CHAR, NATIONAL CHARACTER VARYING, NATIONAL CHAR VARYING | varchar | text | varchar2 |
| char | char | char | char | char | char |
| longblob | Longblob, mediumblob, tinyblob | IMAGE, LONGBINARY, GENERAL, OLEOBJECT, BINARY | image | bytea | blob |
Table 2. autoincrement rows
| Database | Kind |
|---|---|
| MS Acces | Typ Counter |
| MS SQL | Indent(1,1) |
| mysql | autoincrement |
| Postgres | Sequencer |
| Oracle | Sequencer |
| Sqlite | Not supported |
Table 3. Autoincrement Spalten
| Database | Typ |
|---|---|
| MS Acces | Typ Counter |
| MS SQL | Indent(1,1) |
| mysql | autoincrement |
| Postgres | Sequencer |
| Oracle | Sequencer |
| Sqlite | Not supported |
Table 4. Leerstelle in Tabellennamen
| Datenbank | Tabellenname |
|---|---|
| MS Access | [Order Details] |
| MS SQL | [Order Details] |
| mysql | Order_Details |
| postgres | Order_Details |
| Sqlite | [Order Details] |
| Oracle | Order_Details |
For create Schema on specific data base use menu Schema->Operations on Schema->Create DB from Schema. By the menu Schema->Operations on schema->Show SQL definition for schema can you Create sql for the specific data base product. This SQL can be supplemented by data base-specific procedures, that Xdobry does not support. The in such a way adapted SQL must be up-played with data base-own tools.
Data base schema modifing
If you want to change the data base already existing, you must first create Xdobry representation of schema. Use for it the menu Schema->New from DB. They must specify then the data base connection. The changes on that schema are transferred not immediately to the data base. By the menu Schema->Schema operations->Apply Schema changes to DB the change on the data base are applied. By the menu Schema->Schema operations->Show schema changes can you the see the corresponding DDL-SQL statments.
 | This SQL-Statments can be used to update many database synchron (development, Integration, production). |
If the Xdobry XML schema already exist load it first. SchemaEditor offers by loading XML-Schema automatically to connect source database. If another connection is desired or the schema was not developed from a data base, you can connect database with Schema->Connect with data base In the case that schema of the data base is not consistently with that is schema of Xdobry e.g. the schema of the data base reworked on with other tools, you can with the function Schema->Operations on schema->Synchronize schema with data base synchronize XML-repository with data base schema. Afterwords the schema can being adapted like accustomed.
| One cannot record the changes to schema between into several meetings. So the changes on the data base must be up-played, so that you are not lost through terminating the meeting. Schema editor does not possess a function for synchronizing that data base schema to Xdobry Schema. |
SchemaEditor and data migrate
Schema editor possesses various possibilities to migrate the schema and the data between different data base system. Schema editor can keep at the same time 2 data base connections open and transport sentence by sentence the data from data base another. The range of the data too migrated can be adapted. Both tables can be excluded or also individual columns from the migration.
Accomplish the migration
Schema from the source data bank produce. The connection with source data bank must be present
The tables or columns, which are not to be migrated, are to be removed from that schema (you are not actually deleted in source data bank)
The migration start by menu Schema->Migration->Migrate to data base
Arise during the migration errors. These are indicated. The migration can be broken off or continued in this case. In the case of abort the target data bank is not deleted
SchemaEditor and data exporting and importing
Schema editor knows the data on 2 points to export. As XML dump Schema->Migration->Database to XML-SQL the SQL dump Schema->Migration->Database to XML-Dump. For SQL dump the type of target data bank must be indicated.
| The export or import of XML-dump is suitable only for smaller data bases. At now with XML-dumpe into the main memory the entire data base is illustrated at short notice (DOM-object). In this way the Xdobry can with larger data sets fast overflow. An iterative production of XML is possible and becomes for the next version of Xdobry planned. The SQL-dump is provided iterative and causes no excessive demand of main memory. |
With the function Schema->Migration->XML dump to SQL convert one can convert a XML departure to SQL departure.