SchemaEditor
Die Hauptaufgabe des Schema-Editor ist eine XML-Repository zu schaffen und zu verwalten. Weiterhin kann das Schema-Editor benutzt werden um Daten zwischen verschiedenen Datenbanken zu migrieren und Datenabzüge als XML oder SQL zu erstellen. Es wird ein Benutzer des Schema-Editor als ein Datenbank-Administrator oder auch ein Daten-Verwalter vorausgesetzt. Der Benutzer hat Kenntnisse über die Struktur der Daten und ihrer Repräsentation im relationalem Modell. Das Schema-Editor besitzt folgende Funktionalitäten:
Die Data Dictionary (Schema) einer relationalen Datenbank auslesen und in XML-Repository umzuwandeln.
Hinzufügen von semantische Informationen zum Repository. Dabei werden die Reverse Engineering Techniken (siehe. 3.3) benutzt, die entweder ganz automatisch oder durch Befragung des Benutzers verlaufen. Der Benutzer kann auch die semantische Informationen selber hinzufügen .
Hinzufügen und Editieren der Meta-Informationen der Attributen.
Anlegen oder Löschen von Tabellen
Anlegen oder Löschen von Taballenspalten
Anlegen einer DB-Schema aus Xdobry-Repository
Generieren von XML, SQL Datenbankabzügen
Importieren und Exportieren von DB-Schema für alle unterstütze Datenbank
Automatische Migration der Daten und Datenschema zwischen allen unterstützten Datenbanken
 | Im Gegenteil zu Anderen DB-Manager-Programmen arbeitet Schema-Editor nicht direkt auf einer Datenbankschema. Das Datenbankschema wird ausgelesen und in eigene Datenstruktur (Repository) umgewandelt, die auch als XML Datei (.xmlschema) gespeichert und wieder geladen werden kann. Diese Struktur unabhängig von dem Datenbanksystem. Auf diese weise ist eine Verbindungslose Bearbeitung des Schemas möglich.Aus diesem Schema können DDL-Sql für jedes Datenbanksystem erzeugt werden. Auch die Änderungen des Schemas können als DDL-Sql generiert werden. |
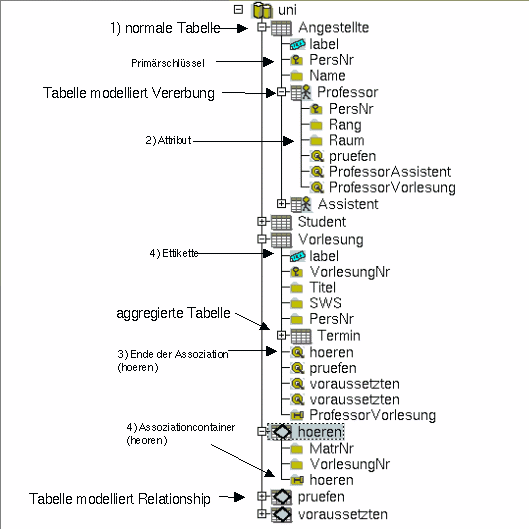
Tabelle (Knoten)
Attribut (Blatt)
Assoziationcontainer
Assoziationtarget
Tabellen-Etikette
Attribut-Gruppen (strukturierte Attribute)
Reverse Engineering
Das relationale Modell ist streng wertorientiert. Es kennt keine Verknüpfungstypen. Die Verknüpfungen werden als Fremdschlüssel repräsentiert. Die Tabellen können als Entities, Relationen, Teilobjekte (bei Generalisierung) oder Eigenschaften (z.B Listen der Attributen) verwendet werden. Bei Reverse Engineering wird die semantische Bedeutung, also die Information, wie das relationale Modell zu interpretieren ist, wiedergewonnen. Diese Informationen werden durch die Namensgebung der Attribute wiedergespiegelt. Weder MySql noch Postgresql unterstützen die Definition von Fremdschlüssel was bei der Erstellung der Formulare großes Nachteil ist. Die Reverse-Engineering Algorithmen basieren bei Xdobry nur auf den relationalen Schema, der Dateninhalt wird nicht ausgewertet. Es wurden drei Reverse-Engineering Algorithmen implementiert. Die Fremdschlüssel-Findung ist eine Basis für andere Algorithmen (außer des Spezialisierung-Findung).
- Fremdschlüssel-Findung
Finde alle Attributen die genau so heißen wie die Primärschlüssel der anderen Tabellen aber nicht die Prim-Attributen sind oder nicht einziges Prim-Attribut sind oder den Namen als id mit Präfix der Tabellennamen haben. Beschränkung: Schüssel der Objekttabellen bestehen aus einzigen Attribut. Keine Rekursive Beziehungen! Aktion: Es wird eine einfache Referenz erstellt. Assoziation-Container erhält den Fremdschlüssel. Assoziation-Target erhält den Primärschlüssel. Es ist eine Basis für die weitere Algorithmen.
- Spezialisierung-Findung
Suche die Spezialisierung. Finde alle Tabellen die einen gleichnamigen Primärschlüssel haben. Sie müssen die Vatertabelle selbst ermitteln. Bei Mehrstufiger Vererbung (Enkelobjekte) muss die Aktion mehrfach durchgeführt werden. Beschränkung: Schüssel der Objekttabellen bestehen aus einzigen Attribut.
- Finde Assoziation-Tabellen
Dieses Reverse Engineering Technik basiert auf dem Schritt "Finde Fremdschlüssel". Es sollten die Tabellen ermittelt werden, die Relationship modellieren (z.B n:m Beziehung). Algorithmus: Finde alle Tabellen, dessen Primärschlüssel aus mehreren Fremdschlüssel besteht oder mehrere Fremdschlüssel und kein eindeutiges Primärschlüssel haben. Aktion: Die Relationship-Tabellen werden besonders gezeichnet. Die n:m oder n:m:z.. Beziehungen werden erkannt. Beziehungen dürfen eigene Attribute haben.
- Aggregation Vorschlagen
Dieses Reverse Engineering Technik basiert auf dem Schritt "Finde Fremdschlüssel". Schlage die Aggregation (Komposition) der Tabellen vor. (eingebettete Tabellen). Das Algorithmus zeigt nur die Vorschläge, die Aggregation-Semantik kann nur von Benutzter bestimmt werden. Vorschläge: Alle Tabellen die nur einen Fremdschlüssel haben. Es können noch weiter Aggregation existieren. Überprüfen sie die 1:n Assoziationen
Definieren von Abstraktionen
Es können drei Arten von Abstraktionen der konzeptionellen Datenbankmodellierung definiert werden: Assoziation, Aggregation uns Spezialisierung. Die Definition erfolgt stufenweise mit Hilfe von Assistenten.
- Assoziation
ist am schwierigsten zu definieren. Es entspricht den Relationship des ER-Modells. Es werden folgende Fragen gestellt.
Ist die Assoziation rekursiv? Es gibt Beziehungen (Relationship) zwischen den Objekten des gleichen Typs.
Gibst es eine Tabelle mit Referenzen? Musste die Assoziation mit Hilfen von zusätzlichen Tabellen abgebildet werden, was beim N:M Beziehungen immer der Fall ist, oder wie bei 1:N Beziehungen gibt es nur ein Verweis in einer der Tabelle
Granularität der Beziehung: beim N:M ist es 2 beim N:M:O ist es 3
Rollennamen: Ein Objekt Student bekommt durch die Beziehung zu Objekt Prüfung einen Rolennamen Prüfling; (nicht obligatorisch)
Existenz Abhängigkeit: Werden bis jetzt nicht weiter unterstützt können aber hier definiert werden
Eine Assoziation wird als Container (Sammlung) mit Verweisen auf Objekte aufgefasst. Die Sammlung kann entweder als getrennte Tabelle mit Verweisen oder als ein Verweis in einem Objekt (1:n) modelliert werden. Um eine Assoziation zu modellieren werden zwei neue Knotentypen hinzugefügt: Assozitaioncontainer bei Verweisen und Assoziationtarget bei Objekten. Zu jeder Assoziation gehört ein Assoziationcontainer und mindestens zwei Assoziatontargets. Die Assoziationen (Assoziationcontainer) besitzen einen eindeutigen Namen. Auf diese weise können auch komplexe Assoziation modelliert werden wie: rekursive 1:n und n:m Beziehungen und Beziehungen der höheren Granularität n:m:s:r. Entsprechung in ER-Modell Abbildung 8 in Abschnitt namens Assoziation (Formular-Links)
- Aggregation
Hier handelt es sich um etwa die Modellierung von eingebetteten oder geschachtelten Tabellen. Sie werden naher von FormServer als eingebettete Formulare dargestellt. Man muss spezifizieren: die Behälter Tabelle, die Element Tabelle und Referenz, Fremdschlüssel in Elementtabelle, das auf Primärschlüssel in Container-Tabelle zeigt. Entsprechung in ER-Modell Abbildung 10 in Abschnitt namens Aggregation
- Spezialisierung
Auch als Vererbung oder Generalisierung bekannt. Es gibt immer einen Vater Objekt und ein Kind Objekt, die in zwei Tabellen modelliert werden. Man muss auch den vererbten Primärschlüssel angeben. Entsprechung in ER-Modell Abbildung 9 in Abschnitt namens Spezialisierung (Vererbung).
DB-Schema Anlegen und Verändern
Xdobry kann benutzt werden um Datenbank zu modellieren. Es können Tabellen und Tabellenspalten angelegt, verändert und gelöscht werden. Xdobry arbeitet nicht direkt auf der Datenbank Dictionary (Schema) sondern hat eigene Datenbanksystem unabhängige Repräsentation des Schemas, die als XML-Datei abgelegt werden kann. Durch diesen Einsatz ist es möglich eine Schema ohne Datenbank zu entwickeln und auf mehrere unterschiedliche Datenbanksystem aufzuspielen. Die Xdobry spezifisches Schema basiert auf ER-Diagramm und enthält mehr semantische Information als die Datadictionary einer Datenbank.
Anlegen einer neuen Schema
Für das einlegen einer neuen Schema ist keine Datenbankverbindung nötig. Durch das Menü Schema->Neu wird neues Datenbankschema angelegt. Benutzten Sie die kontextsensitive Menüs (einen Knoten selektieren und rechte Maustaste klicken) um neue Tabellen und Spalten anzulegen.
Xdobry hat eigenes Datentypen System, der an Mysql-Datenbanksystem angelegt ist aber auch andere Typen (wie Money oder Boolean) unterstützt.
Tabelle 1. Unterstützte Typen und Typenkonventierung
| Xdobry | Mysql | MS Access | MS SQL | Postgres | Oracle |
|---|---|---|---|---|---|
| decimal | Decimal, numeric | Currency, money | monay | money | number |
| double | double | float | float | double | double |
| float | float | real | real | real | float |
| int | int | Integer, int | int | Integer, int | int |
| smallint | Smallint, tinyint | smallint | smallint | smallint | smallint |
| Boolean | smallint | boolean | boolean | Boolean, bool | Number(1) |
| text | Text, mediumtext, tinytext | Memo, LONGTEXT, LONGCHAR, MEMO, NOTE, NTEXT | image | text | clob |
| datetime | Datetime, date, time | datetime | timestamp | timestamp | timestamp |
| timestamp | timestamp | datetime | datetime | timestamp | timestamp |
| enum | enum | Varchar(50) | Varchar(50) | Varchar(50) | Varchar(50) |
| set | set | Varchar(50) | Varchar(50) | Varchar(50) | Varchar(50) |
| varchar | varchar | TEXT(n), ALPHANUMERIC, CHARACTER, STRING, VARCHAR, CHARACTER VARYING, NCHAR, NATIONAL CHARACTER, NATIONAL CHAR, NATIONAL CHARACTER VARYING, NATIONAL CHAR VARYING | varchar | text | varchar2 |
| char | char | char | char | char | char |
| longblob | Longblob, mediumblob, tinyblob | IMAGE, LONGBINARY, GENERAL, OLEOBJECT, BINARY | image | bytea | blob |
Tabelle 2. Autoincrement Spalten
| Database | Kind |
|---|---|
| MS Acces | Typ Counter |
| MS SQL | Indent(1,1) |
| mysql | autoincrement |
| Postgres | Sequencer |
| Oracle | Sequencer |
| Sqlite | Not supported |
Tabelle 3. Autoincrement Spalten
| Database | Typ |
|---|---|
| MS Acces | Typ Counter |
| MS SQL | Indent(1,1) |
| mysql | autoincrement |
| Postgres | Sequencer |
| Oracle | Sequencer |
| Sqlite | Not supported |
Tabelle 4. Leerstelle in Tabellennamen
| Datenbank | Tabellenname |
|---|---|
| MS Access | [Order Details] |
| MS SQL | [Order Details] |
| mysql | Order_Details |
| postgres | Order_Details |
| Sqlite | [Order Details] |
| Oracle | Order_Details |
Um das Schema auf konkreten Datenbank anzulegen benutzten Sie das Menü Schema->Operationen auf Schema->DB aus Schema anlegen. Durch das Menü Schema->Operationen auf Schema->Zeige SQL-Definition für Schema können Sie die CREATE-SQL für die spezifische Datenbank erzeugen. Dieses SQL kann durch datenbankspezifische Prozeduren ergänzt werden, die von Xdobry nicht unterstützt werden. Die so angepasste SQL muss mit datenbankeigenen Werkzeugen aufgespielt werden.
Datenbankschema Ändern
Falls Sie die bereits existierende Datenbank verändern wollen, müssen Sie zuerst die Xdobry Repräsentation der Schema erzeugen. Benutzen Sie dafür das Menü Schema->Neu aus DB. Sie müssen dann die Datenbankverbindung spezifizieren. Die Änderungen auf der Schema werden nicht sofort auf die Datenbank übertragen. Durch das Menü Schema->Schema Operationen->Änderungen auf DB aufspielen werden die Änderung auf die Datenbank aufgespielt. Durch das Menü Schema->Schema Operationen->Zeige Schema Änderungen können Sie sich die Änderung-SQL anschauen.
 | Sie können die Änderung-SQL benutzten um die Änderungsskript für mehrere Datenbanken (Entwicklung, Intergration, Produktion) zu erzeugen. |
Falls die Xdobry XML-Schema bereits existiert, soll Sie als erstes geladen werden. Schema-Editor bietet an nach dem Laden der Schema automatisch sich mit der Datenbank zu verbinden, aus dem das Schema entstanden ist. Falls eine andere Verbindung gewünscht ist oder das Schema nicht aus einer Datenbank entstanden ist, kann mit der Funktion Schema->Verbinde mit Datenbank die Verbindung erstellt werden. Ist das Schema der Datenbank mit der Schema von Xdobry nicht konsistent. Z.B wurde das Schema der Datenbank mit anderen Werkzeugen bearbeitet, kann man mit der Funktion Schema->Operationen auf Schema->Synchronisiere Schema mit Datenbank Das Xdobry Schema mit der Datenbank synchronisieren. Danach kann das Schema wie gewöhnt angepasst werden.
| Man kann die Änderungen an Schema nicht zwischen in mehrere Sitzungen festhalten. So müssen die Änderungen auf der Datenbank aufgespielt werden, damit Sie nicht durch das Beenden der Sitzung verloren gehen. Schema Editor besitzt keine Funktion für das Synchronisieren der Datenbankschema an Xdobry Schema. |
DB-Schema und Daten migrieren
Schema-Editor besitzt vielfältige Möglichkeiten das Schema und die Daten zwischen verschiedenen Datenbanksystem zu migrieren. Schema-Editor kann gleichzeitig 2 Datenbankverbindungen offen halten und die Daten satzweise von einen Datenbank auf eine andere zu transponieren. Dabei kann der Umfang der zu migrierten Daten angepasst werden. Es können sowohl Tabellen oder auch einzelne Spalten aus der Migration ausgeschlossen werden.
Durchführen der Migration
Eine Schema aus der Quelldatenbank erzeugen. Die Verbindung mit Quelldaten Bank muss vorhanden sein
Die Tabellen oder Spalten, die nicht migriert werden sollen, sollen aus der Schema entfernt werden (Sie werden nicht tatsächlich im Quelldatenbank gelöscht)
Die Migration starten durch Menü Schema->Migration->Migriere Datenbank
Treten während der Migration Fehler auf. Werden diese angezeigt. Die Migration kann in diesem Fall abgebrochen oder fortgesetzt werden. Bei Abbruch wird die Zieldatenbank nicht gelöscht
DB-Schema und Daten Exportieren und Importieren
Schema-Editor kann die Daten auf 2 weisen exportieren. Als XML-Abzug Schema->Migration->Datenbank als XML dumpen der SQL-Abzug Schema->Migration->Datenbank als XML dumpen. Bei SQL-Abzug muss der Zieldatenbank-Typ angegeben werden.
| Der Export oder Import mittels XML-Abzug ist nur für kleinere Datenbanken geeignet. Bei XML-Abzug wird in den Arbeitsspeicher kurzfristig die gesamte Datenbank abgebildet (DOM-Objekt). Auf diese Weise kann das Xdobry bei größeren Datenmengen schnell überlaufen. Eine Iterative Erzeugung von XML ist möglich und wird für die nächste Version von Xdobry geplant. Der SQL-Abzug wird iterativ erstellt und verursacht keine übermäßige Beanspruchung von Arbeitsspeicher. |
Mit der Funktion Schema->Migration->XML-Dump zu SQL umwandeln kann man ein XML-Abzug zu SQL-Abzug konvertieren.